212. 单词搜索 II
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例 1:
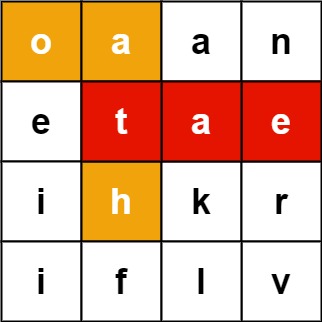
输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"]
输出:["eat","oath"]
示例 2:
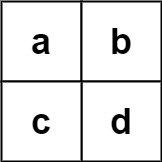
输入:board = [["a","b"],["c","d"]], words = ["abcb"]
输出:[]
提示:
m == board.lengthn == board[i].length1 <= m, n <= 12board[i][j]是一个小写英文字母1 <= words.length <= 3 * 1041 <= words[i].length <= 10words[i]由小写英文字母组成words中的所有字符串互不相同
字典树 回溯 困难
利用回溯算法搜索路径,利用字典树加速判断当前路径是否在字典树中.
将匹配到的单词从前缀树中移除,来避免重复寻找相同的单词。
(不用字典树也能做)
代码
from collections import defaultdict
class Trie:
def __init__(self):
self.children = defaultdict(Trie)
self.word = ""
def insert(self, word):
cur = self
for c in word:
cur = cur.children[c]
cur.is_word = True
cur.word = word
class Solution:
def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
trie = Trie()
for word in words:
trie.insert(word)
def dfs(now, i1, j1):
if board[i1][j1] not in now.children:
return
ch = board[i1][j1]
nxt = now.children[ch]
if nxt.word != "": # 找到一个答案
ans.append(nxt.word)
nxt.word = "" # 将匹配到的单词从前缀树中移除
if nxt.children: # 搜索下一步
board[i1][j1] = "#" # 置为‘#’避免重复搜索
for i2, j2 in [(i1 + 1, j1), (i1 - 1, j1), (i1, j1 + 1), (i1, j1 - 1)]:
if 0 <= i2 < m and 0 <= j2 < n:
dfs(nxt, i2, j2)
board[i1][j1] = ch # 恢复原来的字符
if not nxt.children:
now.children.pop(ch) # 移除当前分支
ans = []
m, n = len(board), len(board[0])
for i in range(m):
for j in range(n):
dfs(trie, i, j)
return ans